近日,浙江大学伊利诺伊大学厄巴纳香槟校区联合学院(ZJUI)王宏伟教授知识工程与知识系统实验室(DSKE LAB)的一项工作: MedM2G: Unifying Medical Multi-Modal Generation via Cross-Guided Diffusion with Visual Invariant,被计算机视觉领域顶会CVPR2024接收。该工作构建了一个医学多模态生成框架,在同一个模型中对齐、提取和生成医学多模态。该论文第一作者为DSKE LAB 2022级博士生詹晨璐,通讯作者为浙江大学王宏伟教授和王高昂助理教授、研究员。
近年来,各种基于去噪扩散模型的高级医学领域生成工作显著提高了医学诊断任务的效率。然而,这些医学生成模型大多依赖于不同的单流管道,用于专门的生成任务,过程繁琐且速度缓慢。在需要整合多种医学模态进行分析的真实世界医学场景中,这种生成方法在其外延上面临着诸多实质性的限制。此外,最新的多模态生成方法在提取特定医学知识和利用有限的医学配对数据实现跨模态生成方面的能力还非常有限。这些不足使得构建一个能够处理多种医学模态任务的统一医学生成模型成为迫切需要。这样的模型仍然存在一些困难的挑战:( 1 )多种医疗模式之间的巨大差异对实现一致性提出了重大挑战,并带来了昂贵的成本。( 2 )与一般领域的图像不同,医学影像模态( CT、MRI、X光等图像)具有各自独特的临床特性。传统的统一对齐方法往往会导致混叠。( 3 )一般多模态生成式预训练模型通常具有大规模匹配良好的跨模态数据库,而医学跨模态配对训练数据集非常缺乏,使得医学多模态的生成式能力难以再训练。
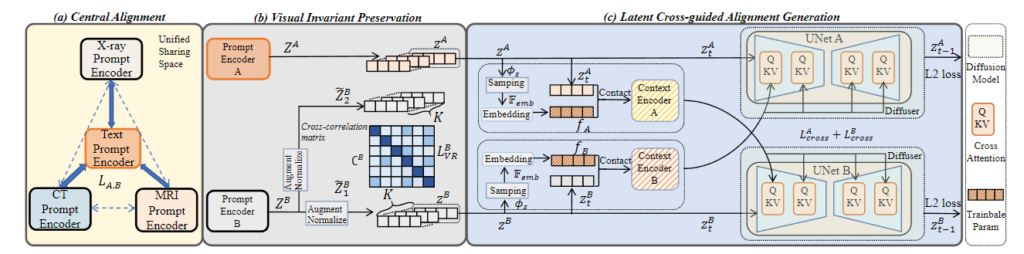
▲ 论文的主要框架
为了解决上述挑战,该论文提出了一个统一的医学多模态生成模型MedM2G,该模型创新地在统一的模型中对齐、提取和生成多种医学模态。MedM2G通过与多种扩散模型交互实现医学多模态生成。本文主要的动机是解决以下问题:1 ) MedM2G可以生成任意模态的成对数据。利用生成的数据进行预训练,提高了下游任务(分类、分割、检测、翻译)的性能。2 ) MedM2G可以对稀缺的医疗模式进行代际补偿。3 ) MedM2G可以融合生成多模态用于医学综合分析。4 ) MedM2G可以在一个统一的模型内处理多个任务,并实现了SOTA 结果。本文具体的贡献可以主要包含以下几个方面:
-
提出了第一个能够对齐、提取和生成多种医学模态的统一医学多流生成框架MedM2G。
-
提出了以自适应参数为条件的多流交叉引导扩散策略,用于高效的医学多模态生成,并配合医学视觉不变量保存来维护特定的医学知识。具体来说,我们首先提出在输入和输出共享空间中有效采用的中心对齐,它将每个模态的嵌入与文本嵌入进行简单对齐,从而实现所有模态的对齐。值得注意的是,为了保持跨模态概念生成所特有的3种医学影像模态的特定医学知识,我们提出了医学视觉不变量保持,通过最小化两个增强视图的非对角线元素来更好地提取。此外,增强医学跨模态的交互是至关重要的,因此,我们将自适应表示和可共享的交叉注意力子层限制在每个跨模态扩散器中。结合本文提出的多流训练策略,我们的模型可以无缝地处理多个无跨模态配对数据集的医疗生成任务。
-
MedM2G在5个医疗生成任务的10个数据集上都获得了优越的性能。 除此之外,MedM2G可以生成的成对的医学模态数据来进行预训练,有效提高了下游分类、分割、检测、转化任务的性能。
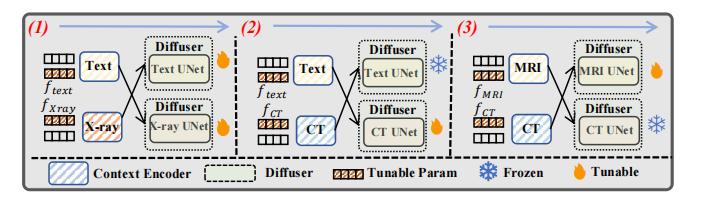
▲ 多流训练策略
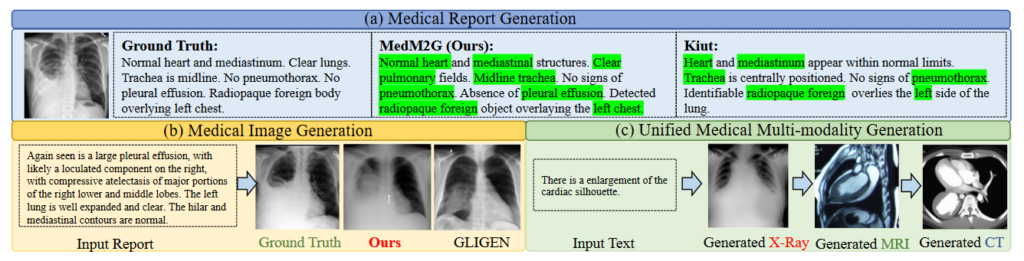
▲ 医学模态生成结果

▲ 利用生成的医学数据辅助下游任务
作者信息:
詹晨璐,ZJUI和浙江大学计算机科学与技术学院计算机科学与技术专业联合培养博士研究生,由ZJUI王宏伟教授、王高昂助理教授、林毓助理教授联合指导,研究方向为多模态、医学图像处理。
论文信息:
标题:MedM2G: Unifying Medical Multi-Modal Generation via Cross-Guided Diffusion with Visual Invariant

