近日,浙江大学伊利诺伊大学厄巴纳香槟校区联合学院(ZJUI)王宏伟教授知识工程与知识系统实验室(DSKE LAB)的一项工作"API Is Enough: Conformal Prediction for Large Language Models Without Logit-Access",被自然语言处理领域顶会EMNLP2024 Findings接收。该工作解决了在logit不可访问情况下量化大语言模型不确定性的普遍挑战。论文第一作者为DSKE LAB 2023级硕士生苏嘉源,指导老师为浙江大学王宏伟教授。
共形预测(CP)因其模型无关性和分布无关性特性,被视为适用于各种大语言模型(LLMs)和数据分布的方法。然而,现有的用于LLMs的CP方法通常假设可以访问logit,但对于某些仅提供API的大语言模型来说,logit是无法获取的。此外,logit已知存在校准问题,可能会导致CP性能下降。为应对这些挑战,我们提出了一种新的CP方法:(1) 针对无logit访问的仅API大语言模型进行优化;(2) 尽可能缩小预测集的规模;(3) 确保用户定义覆盖率的统计保证。该方法的核心思想是利用粗粒度(如样本频率)和细粒度不确定性概念(如语义相似度)来构建不一致性测度。在封闭式和开放式问答任务上的实验结果表明,我们的方法在大多数情况下优于基于logit的CP基线。
论文简介
大语言模型(LLMs)取得了显著的进展,展现了自然语言生成的研究潜力。然而,它们经常生成不准确、不真实或不基于事实的信息,这种现象被称为“幻觉”。因此,量化LLMs的不确定性对于确保其生成负责任的回应至关重要。
然而,由于复杂的数据分布和模型内部机制,以及通常难以获取logit信息,LLMs的不确定性量化(UQ)充满挑战。一个潜在的解决方案是使用CP,它以模型无关性和分布无关性著称,并提供严格的覆盖率保证。现有的大多数用于LLMs的CP方法依赖于访问模型的logit来测量非一致性得分。然而,对于一些仅提供API的LLMs,终端用户几乎不可能访问logit信息。即使logit信息可获取,也可能存在校准问题,这可能导致CP在估计预测集时性能下降,进而影响预测的效率和有效性。
为了在没有logit访问的情况下实现CP,我们提出对每个输入抽样一定次数(例如30次),并将每个响应的频率作为粗粒度的不确定性概念。这种方法减少了抽样成本并消除了对logits的依赖。然而,仅使用频率作为非一致性测度会导致得分集中在某些值上,降低预测集的效率。为了解决这个问题,我们提出了两个细粒度的不确定性概念:归一化熵(NE),用于衡量不同提示之间的一致性,以及语义相似度(SS),用于衡量响应与同一提示内最频繁响应之间的相似度。通过结合这些不同的不确定性信息,所提出的非一致性得分函数可以更好地区分不同响应的不确定性。

▲提出的问题和解决方法的说明
我们的贡献总结如下:
-
这是首个针对没有logit访问的LLMs的CP工作,提供了小规模预测集的覆盖率保证。
-
提出了一种新颖的CP方法,使用粗粒度和细粒度的不确定性概念作为非一致性测度。还从理论上证明了:(1) 使用响应频率来近似模型输出概率在计算上是不可行的;(2) 我们的方法确保了严格的统计覆盖率保证。
-
在封闭式和开放式问答任务上进行了实验,证明了方法的有效性。值得注意的是,我们在大多数情况下超越了所有基线,包括四种访问logit的方法和一种不访问logit的方法。
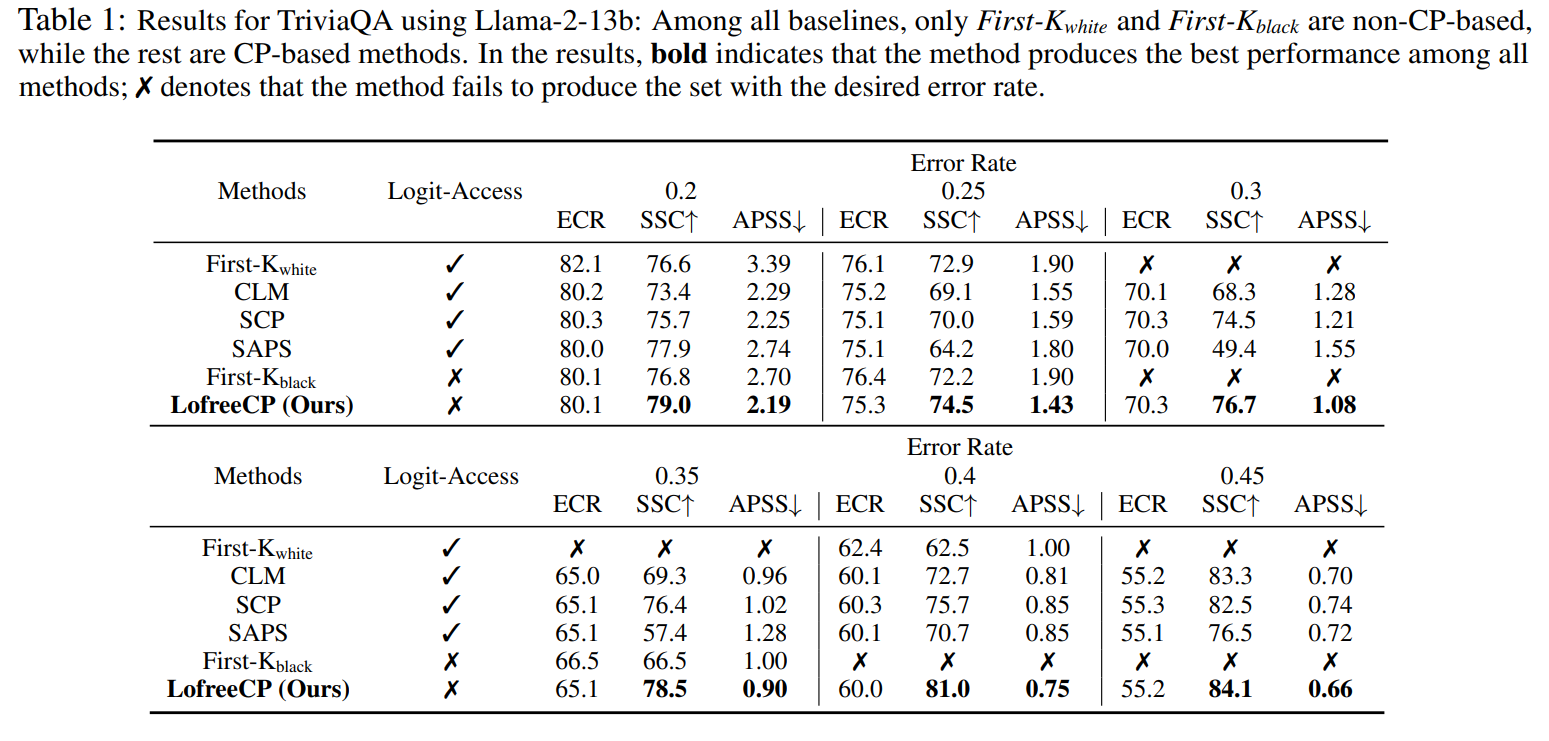
▲Llama-2-13b模型在TriviaQA数据集上的结果

▲Llama-2-13b模型在WebQuestions数据集上的结果
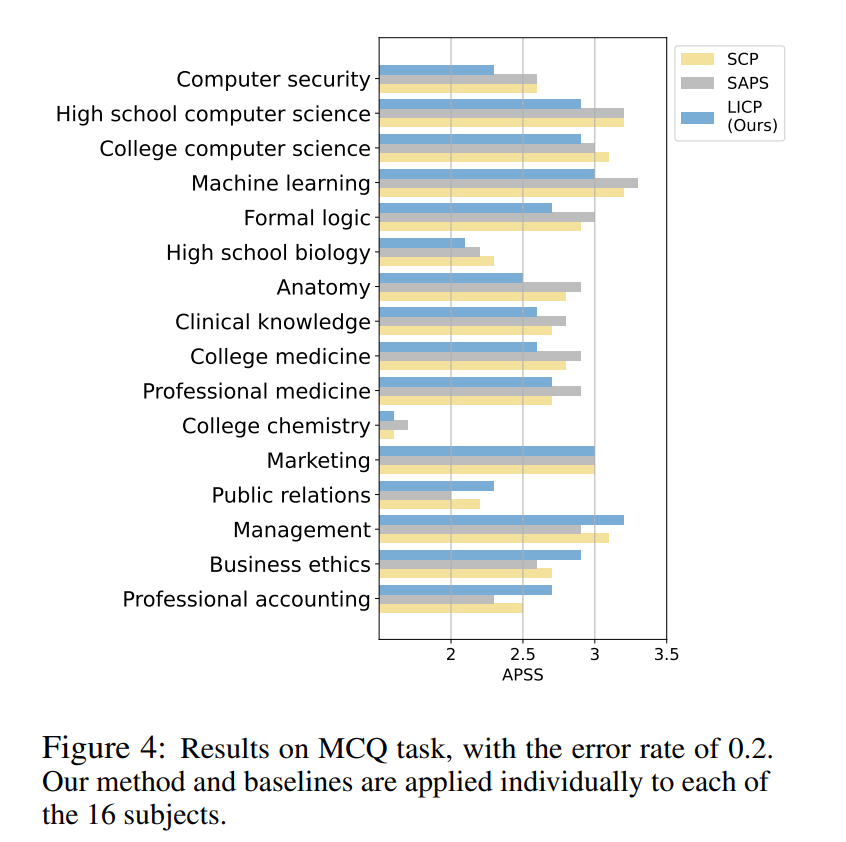
▲Llama-2-13b模型在MCQ任务上的结果
作者信息
苏嘉源,ZJUI人工智能专业硕士研究生,指导教授为ZJUI王宏伟教授,研究方向为自然语言处理、大语言模型。
团队介绍
DSKE LAB成立于2018年,聚焦自然语言处理、知识图谱构建、基于知识的决策与推理、知识驱动的协同建模与仿真、数据驱动的状态监测和故障诊断等方面的研究,研究成果发表于包括 ACL、EMNLP、CVPR、IJCAI、TII、TNNLS、TASE等在内的各项国际顶级会议和期刊。其中,团队近年围绕自然处理领域的低资源命名实体识别、低资源关系抽取、开放知识图谱推理等问题开展研究,研究成果先后在ACL、EMNLP等高水平会议发表。
论文信息
论文标题:
API Is Enough: Conformal Prediction for Large Language Models Without Logit-Access
论文地址:

