近日,浙江大学伊利诺伊大学厄巴纳香槟校区联合学院(ZJUI)王宏伟教授知识工程与知识系统实验室(DSKE LAB)的一项工作" SemanticMask: A Contrastive View Design for Anomaly Detection in Tabular Data",被机器学习领域顶会IJCAI2024接收。该论文第一作者为DSKE LAB 2021级博士研究生陶舒婷,通讯作者为浙江大学王宏伟教授和孟祥明助理教授。
论文简介
基于数据增强技术的对比学习最近在图像领域的异常检测方面取得了实质性的进展。然而,由于缺乏空间结构,为表格数据设计有效的数据增强方法仍然具有挑战性。传统技术,如随机遮盖,忽视了特征之间的相关性,无法准确地表示数据。为了解决这个问题,我们提出了一种新颖的增强技术,称为SemanticMask,它利用列名中的语义信息生成更好的增强视图。SemanticMask旨在确保视图之间共享的信息包含足够的信息用于异常检测,而不会产生冗余。在论文中,我们分析了共享信息与异常检测性能之间的关系,并从经验上证明了针对表格异常检测任务的良好视图是特征相关的。我们的实验结果验证了SemanticMask优于表格数据的传统异常检测方法和数据增强技术。我们还进一步评估了多类别异常检测任务,SemanticMask也明显优于基线。
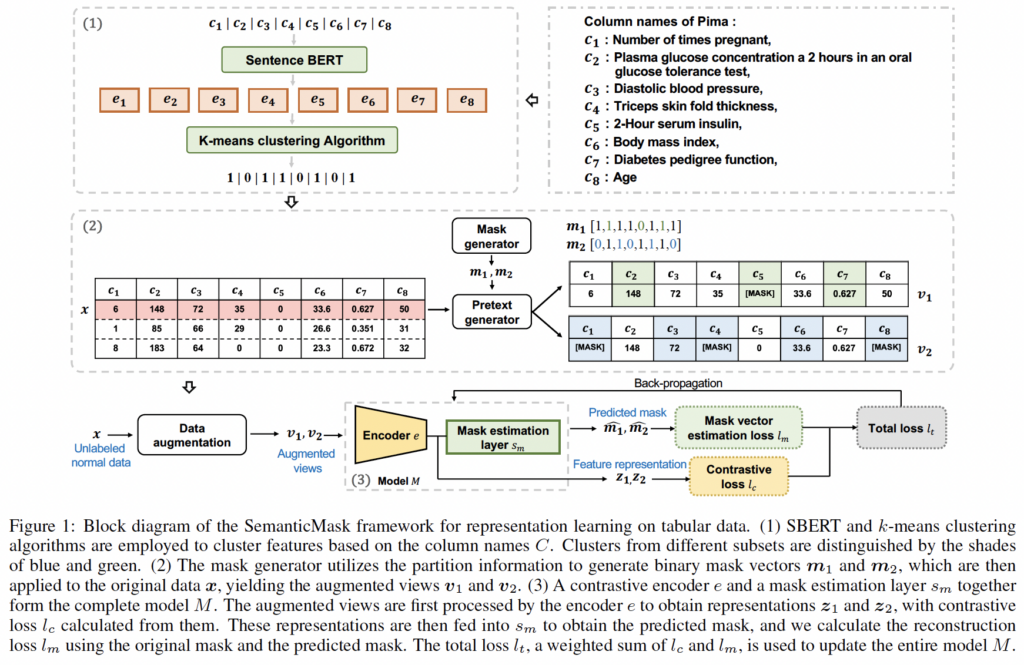
▲ SemanticMask方法总流程图
对于现实世界的表格数据,列名通常携带有价值的语义信息。这意味着具有语义相似列名的特征通常是相关的,当异常发生时会表现出相似的异常值模式。利用这种语义关联,我们提出了一种基于语义的掩码方法(称为SemanticMask)用于基于对比学习的异常检测。具体来说,SemanticMask使用语言模型和聚类算法将特征分成k个簇,将具有语义相似列名的特征分组到同一个簇中。在设计对比视图时,由于异常特征是未知的,因此共享信息包含整个语义范围内的完整特征覆盖至关重要,即增强视图之间的共享特征至少包含每个簇中的一个特征。SemanticMask通过将这些簇随机且公平地划分为两个不同的子集来实现这一点。然后,每个增强视图选择不同的子集,并对其各自选择的子集中的每个簇应用预定的掩码比例,同时保持未选择的簇不受影响。因此,SemanticMask降低了每个簇的信息丢失的可能性,同时防止了冗余,从而在视图之间共享信息的数量上实现了平衡。相比之下,传统的数据增强技术,如随机掩码,忽视了这种语义连接。它们随机选择特征作为共享信息,因此共享特征更有可能仅来自部分簇,导致生成的表示不足以捕获关键的异常特征。主要贡献总结如下:
(1) 我们提出了SemanticMask,一种将列名的语义信息纳入考虑的方法,用于创建表格领域异常检测的有效增强视图。此外,我们引入了两种扩展变体:一种结合掩码估计模块,以解决分类特征自然包含导致歧义的零值的情况;另一种整合了描述异常检测任务的一句话提示作为先验知识,有助于选择共享特征。
(2) 我们分析了共享信息的数量与不同设置下SemanticMask的下游异常检测性能之间的关系。我们还从经验上证明了基于对比学习的异常检测的良好视图是特征相关的。
(3) SemanticMask优于表格数据的最先进异常检测方法和增强技术。此外,我们还将SemanticMask扩展到多类异常检测,并进一步展示了其效果和多功能性。
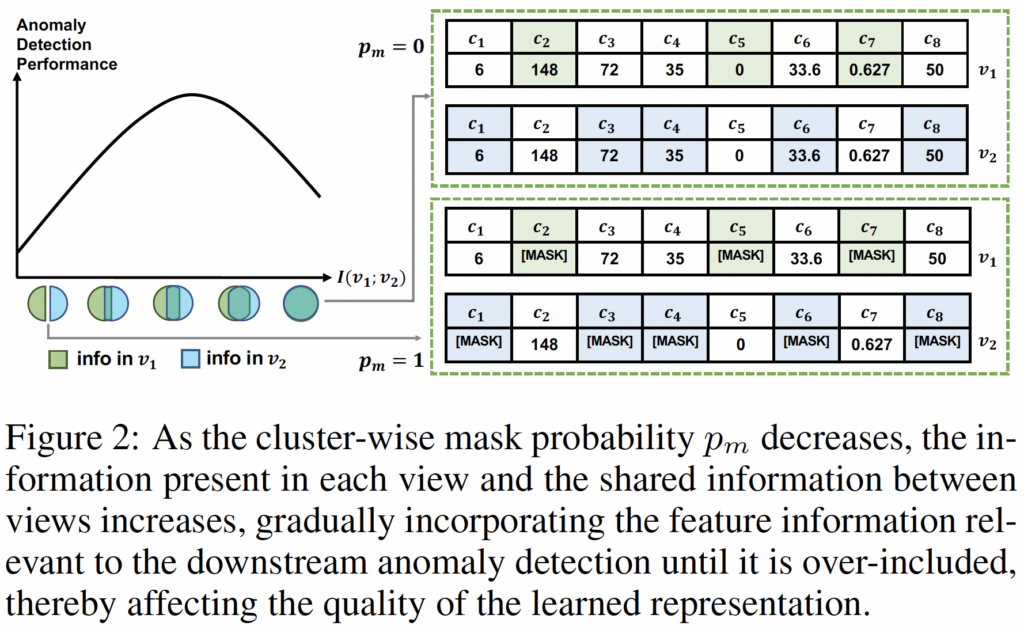
▲掩码概率与共享信息的关系
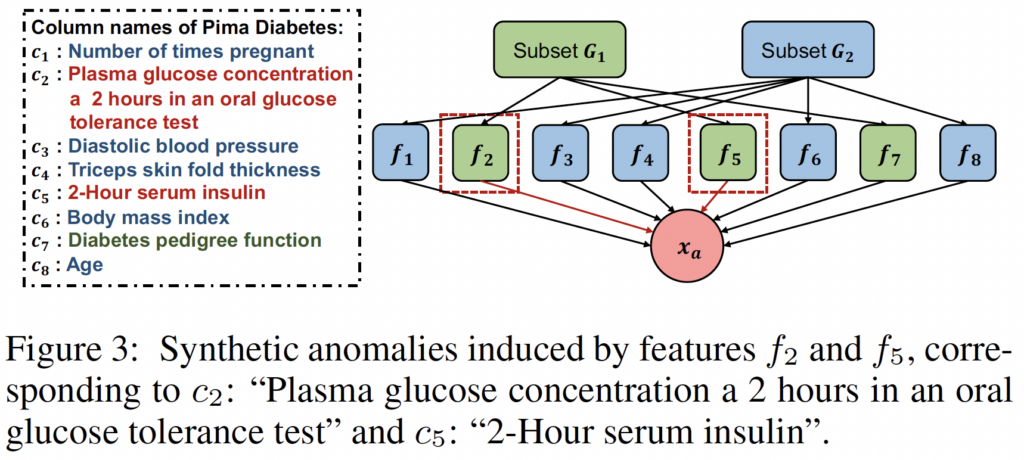
▲人造异常设计说明
作者信息:
陶舒婷,ZJUI和浙江大学计算机科学与技术学院计算机科学与技术专业联合培养博士研究生,由ZJUI王宏伟教授、孟祥明助理教授联合指导,研究方向为对比学习,扩散模型。

